
studio.heelab
[ML] 군집화(Clustering) 본문
CH07. 군집화
01. K-평균 알고리즘 이해
K-평균은 군집 중심점이라는 특정한 임의의 지점을 선택해 해당 중심에 가장 가까운 포인트들을 선택하는 군집화 기법

사이킷런 KMeans 클래스 소개
초기화 파라미터
- n_clusters: 군집화할 개수, 군집 중심점의 개수
- init: 초기에 군집 중심점의 좌표를 설정할 방식
- max_iter: 최대 반속 횟수, 이 횟수 이전에 모든 데이터의 중심점 이동이 없으면 종료
주요 속성 정보
- labels_: 각 데이터 포인트가 속한 군집 중심점 레이블
- cluster_centers_: 각 군집 중심점 좌표
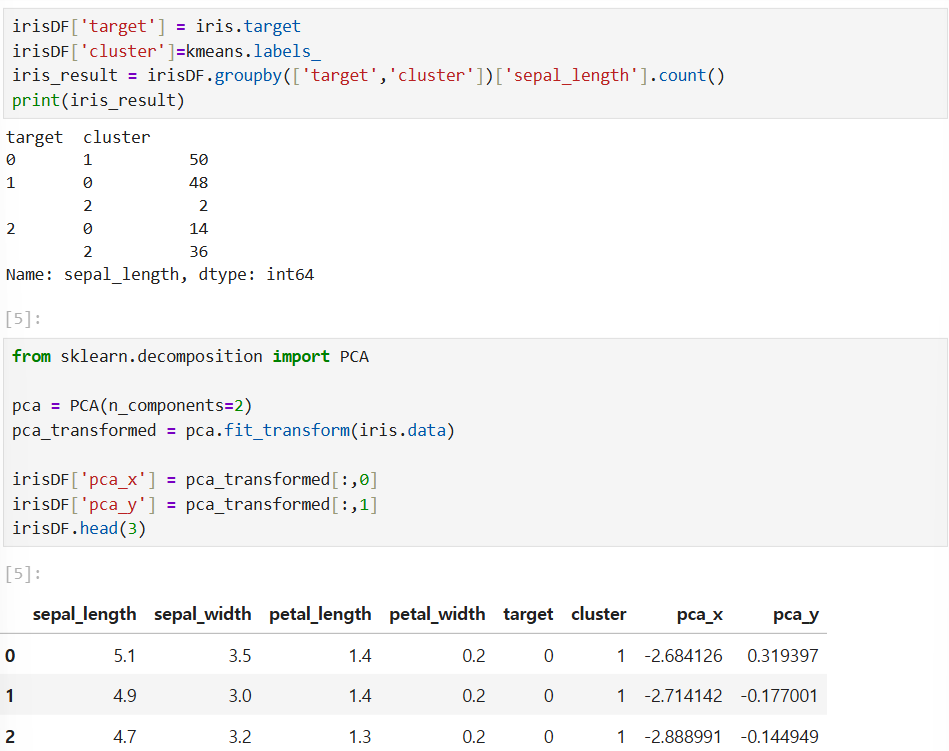
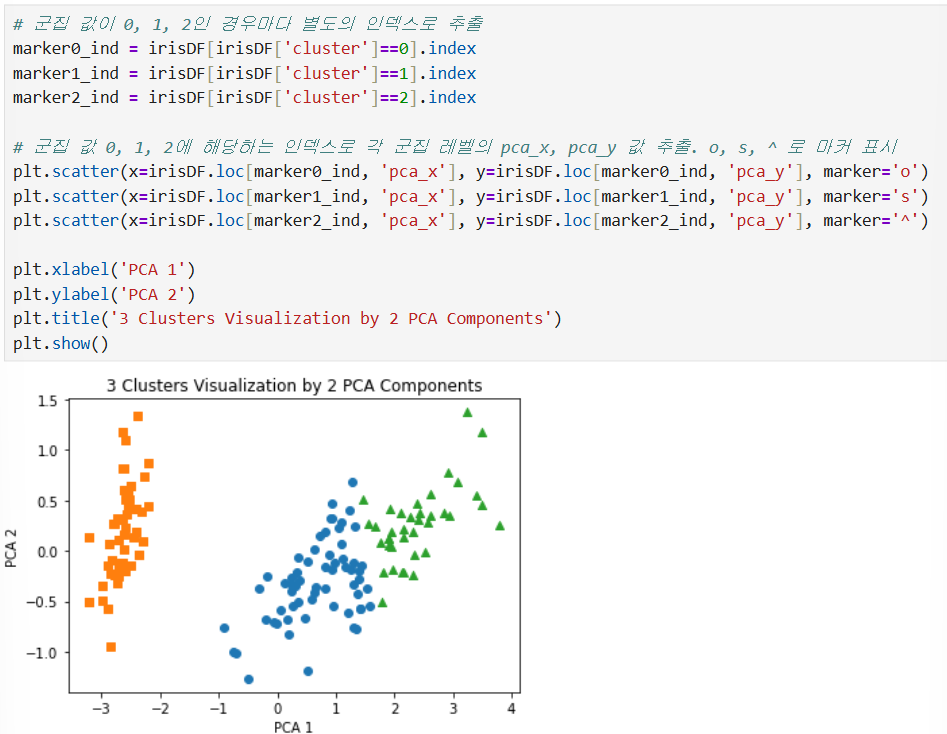
K-평균을 이용한 붓꽃 데이터 세트 군집화
꽃받침과 꽃잎 길이와 너비에 따른 품종 분류 데이터 세트

kmeans = KMeans(n_clusters=3, init='k-means++', max_iter=300,random_state=0)
kmeans.fit(irisDF)
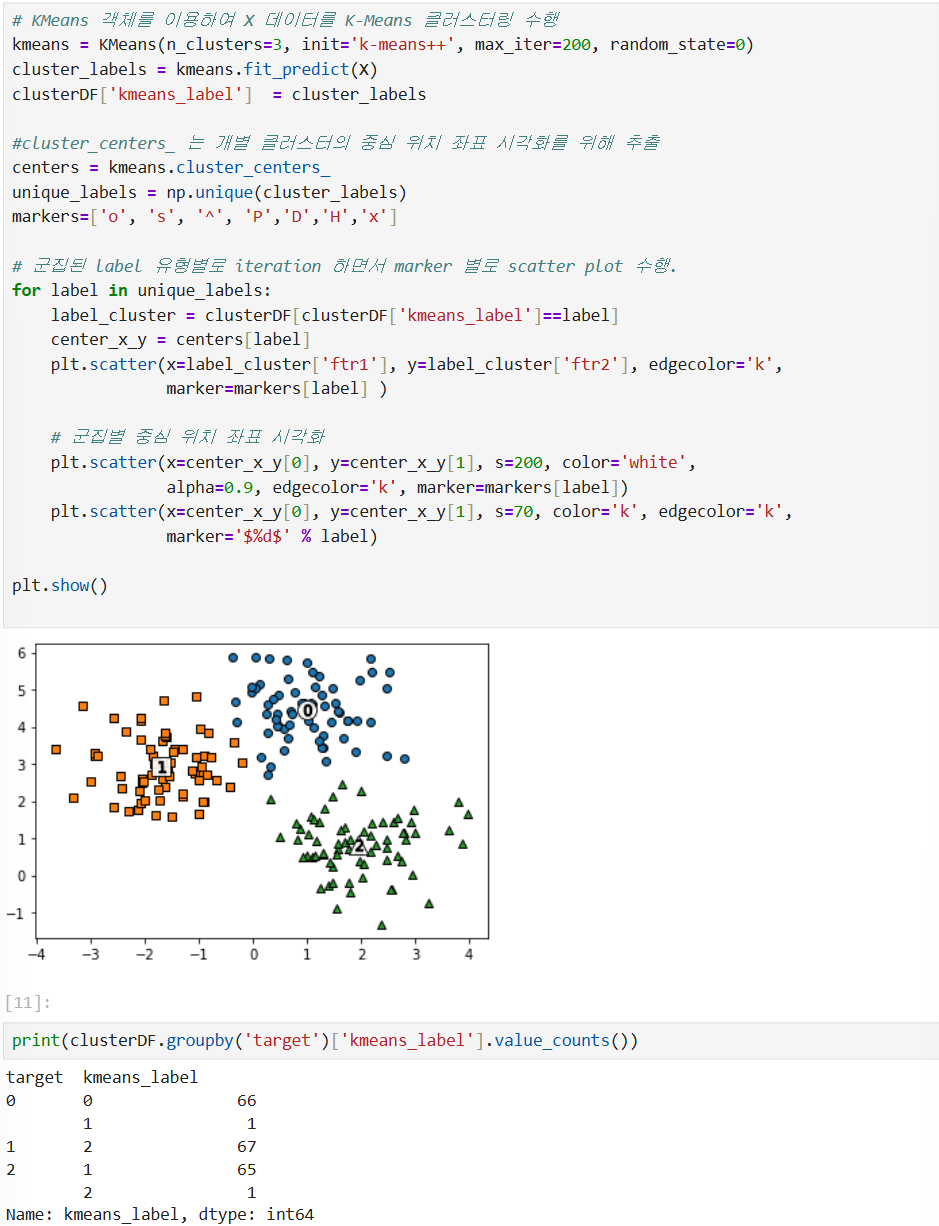
군집화 알고리즘 테스트를 위한 데이터 생성
- n_samples: 생성할 총 데이터의 개수
- n_features: 데이터의 피처 개수
- centers: int 값
- cluster_std: 생성될 군집 데이터의 표준 편찬


02. 군집 평가(Cluster Evaluation)
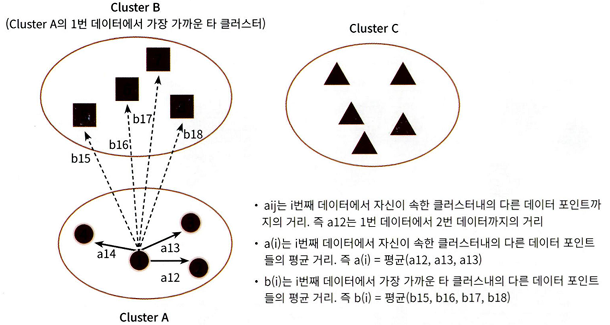
실루엣 분석의 개요
각 군집 간의 거리가 얼마나 효율적으로 분리돼 있는지를 나타낸다
실루엣 계수(개별 데이터가 가지는 군집화 지표) 기반

좋은 군집화의 조건
-전체 실루엣 계수의 평균값, 즉 사이킷런의 silhouette_score() 값은 0-1 사이의 값을 가짐
-개별 군집의 평균값의 편차가 크지 않아야 한다
붗꽃 데이터 세트를 이용한 군집 평가
sklearn, metrics 모듈의 silhouette_samples()와 silhouette_score()를 이용한다


군집별 평균 실루엣 개수의 시각화를 통한 군집 개수 최적화 방법
-주어진 데이터에 대해서 군집의 개수 2개를 정했을 때
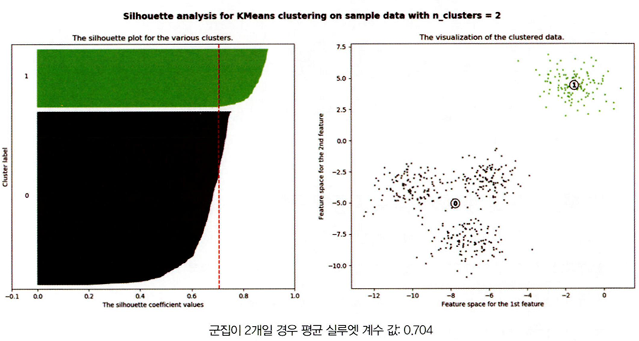
-군집 개수가 3개, 4개일 경우

# make_blobs 을 통해 clustering 을 위한 4개의 클러스터 중심의 500개 2차원 데이터 셋 생성
from sklearn.datasets import make_blobs
X, y = make_blobs(n_samples=500, n_features=2, centers=4, cluster_std=1, \
center_box=(-10.0, 10.0), shuffle=True, random_state=1)
# cluster 개수를 2개, 3개, 4개, 5개 일때의 클러스터별 실루엣 계수 평균값을 시각화
visualize_silhouette([ 2, 3, 4, 5], X)
from sklearn.datasets import load_iris
iris=load_iris()
visualize_silhouette([ 2, 3, 4,5 ], iris.data)03. 평균 이동
평균 이동(Mean Shift)의 개요
중심을 군집의 중심으로 지속적으로 움직이면서 군집화 수행
중심을 데이터가 모여 있는 밀도가 가장 높은 곳으로 이동시킴
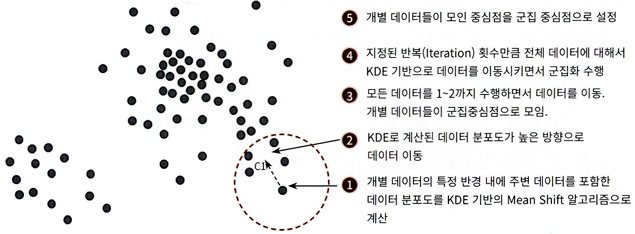
KDE는 커널 함수를 통해 어떤 함수의 확률 밀도 함수를 추정하는 대표적 방법

대역폭 h를 계산하는 것은 KDE 기반의 평균 이동 군집화에서 매우 중요

bandwidth값 최적화 중요
estimate_bandwidth()

import matplotlib.pyplot as plt
%matplotlib inline
clusterDF['meanshift_label'] = cluster_labels
centers = meanshift.cluster_centers_
unique_labels = np.unique(cluster_labels)
markers=['o', 's', '^', 'x', '*']
for label in unique_labels:
label_cluster = clusterDF[clusterDF['meanshift_label']==label]
center_x_y = centers[label]
# 군집별로 다른 마커로 산점도 적용
plt.scatter(x=label_cluster['ftr1'], y=label_cluster['ftr2'], edgecolor='k', marker=markers[label] )
# 군집별 중심 표현
plt.scatter(x=center_x_y[0], y=center_x_y[1], s=200, color='gray', alpha=0.9, marker=markers[label])
plt.scatter(x=center_x_y[0], y=center_x_y[1], s=70, color='k', edgecolor='k', marker='$%d$' % label)
plt.show()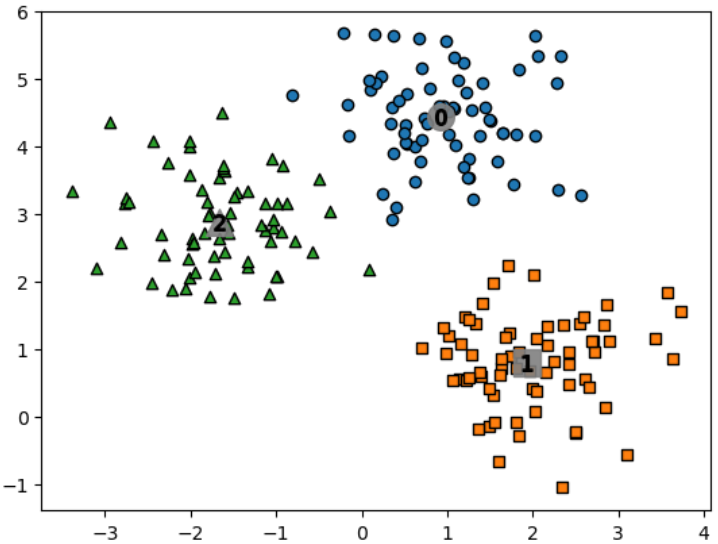
04. GMM(Gaussian Mixture Model)
GMM 소개
군집화 적용하려고 하는 데이터가 여러 개의 가우시안 분포를 가진 데이터 집합들이 섞여서 생성된 것이라는 가정하에 군집화를 수행하는 방식
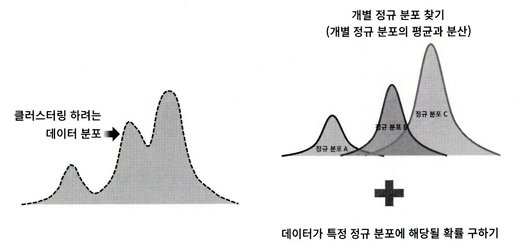
모수 추정
-개별 정규 분포의 평균과 분산
-각 데이터가 어떤 정규 분포에 해당되는지의 확률
GMM을 이용한 붓꽃 데이터 세트 군집화

GMM과 K-평균의 비교(459p)

05. DBSCAN
DBSCAN 개요
특정 공간 내에 데이터 밀도 차이를 기반 알고리즘으로 하고, 복잡한 기하학적 분포도를 가진 데이터 셋에 대해서 군집화 잘함

입실론 주변 영역(epsilon): 개별 데이터 중심으로 입실론 반경을 가지는 원형의 영역
최소 데이터 개수: 개별 데이터의 입실론 주변 영역에 포함되는 타 데이터의 개수
핵심 포인트: 주변 영역 내 최소 데이터 개수 이상의 타 데이터를 가지고 있을 경우 해당 데이터를 핵심 포인트
이웃 포인트: 주변 영역 내에 위치한 타 데이터
경계 포인트: 주변 영역 내 최소 데이터 갯 이상의 이웃 포인트 가지고 있지 않지만 핵심 포인트를 이웃 포인트를 가지고 있는 데이터
잡음 포인트
DBSCAN 적용하기 - 붗꽃 데이터 세트
DBSCAN 적용하기 - make_circle() 데이터 세트
06. 군집화 실습 - 고객 세그먼테이션(474p)
고객 세그먼테이션의 정의와 기법
데이터 세트 로디오가 데이터 클렌징
RFM 기반 데이터 가공
RFM 기반 고객 세그먼테이션
'AI' 카테고리의 다른 글
| [ML] 추천 시스템(Recommendations) (0) | 2026.03.03 |
|---|---|
| [ML] 텍스트 분석(Text Analytics) (0) | 2026.03.03 |
| [ML] 차원 축소(Dimension Reduction) (1) | 2026.03.02 |
| [ML] 회귀(Regression) (0) | 2026.03.02 |
| [ML] 분류(Classification) (0) | 2026.03.01 |

