
studio.heelab
[ML] 텍스트 분석(Text Analytics) 본문
CH08.텍스트 분석
01. 텍스트 분석 이해
텍스트 분류: 문서가 특정 분류 또는 카테고리에 속하는 것을 예측하는 기법
감성 분석: 텍스트에서 나타내는 감정/판단/믿음/의견/기분 등의 주관적인 요소를 분석하는 기법
텍스트 요약: 텍스트 내에서 중요한 주제나 중심 사상을 추출하는 기법
텍스트 군집화와 유사도 측정: 비슷한 유형의 문서에 대해 군집화를 수행하는 기법
텍스트를 변환하는 것: 피처 벡터화 또는 피처 추출
변환하는 방법 BOW
텍스트 분석 수행 프로세스
1. 텍스트 사전 준비 작업(텍스트 전처리): 미리 클렌징, 대소문자 변경, 특수문자 삭제 등 클렌징 작업, 단어 등의 토큰화 작업, 의미 없는 단어 제거 작업, 어근 추출 등 텍스트 정규화 작업 수행 통칭
2. 피처 벡터화/추출: 사전 준비 작업으로 가공된 텍스트에서 피처 추출하고 벡터값 할당. 방벙으로는 BOW, Word2Vec이 있다
3. ML 모델 수립 및 학습/예측/평가: 피처 벡터화된 데이터 셋에 ML 모델을 적용해 학습/예측 및 평가를 수행

파이썬 기반의 NLP, 텍스트 분석 패키지
NLTK
Gensim
SpaCy
02. 텍스트 사전 준비 작업(텍스트 전처리) - 텍스트 정규화
클렌징
텍스트 분석에 오히려 방해가 되는 불필요한 문자, 기호 등을 사전에 제거하는 작업
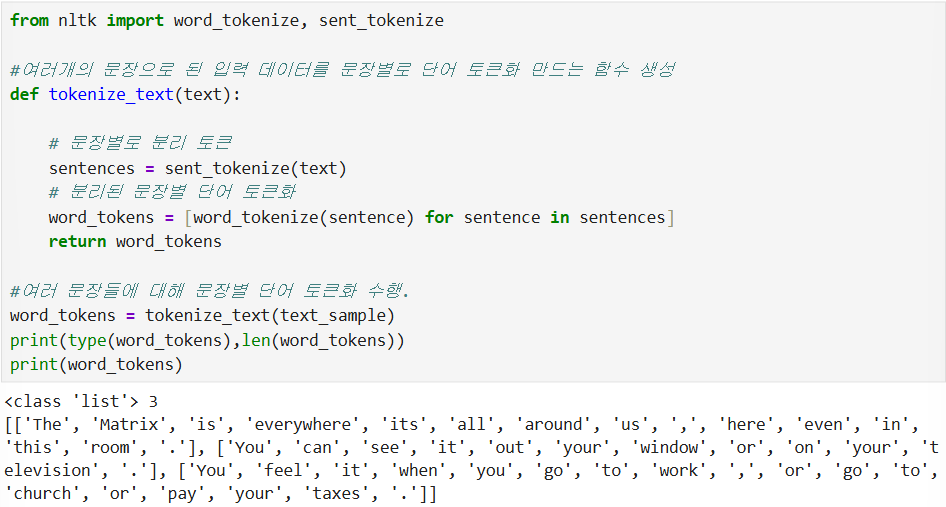
텍스트 토큰화
문서->문장 분리하는 문장 토큰화
문장->단어 분리하는 단어 토큰화
NLTK가 API 제공
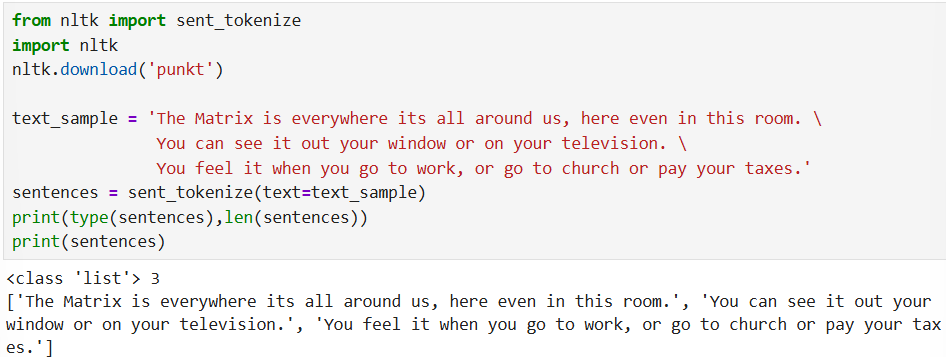
문장 토큰화
마침표, 개행 문자 등의 기호에 따라 분리하는 것이 일반적
sent_tokenize를 이용해 토큰화 수행
단어 토큰화
공백, 콤마, 마침표, 개행문자 등으로 단어 분리
정규 표현식을 이용해 토큰화 수행
word_tokenize() 이용

스톱 워드 제거
스톱 워드: 분석에 큰 의미가 없는 단어
스톱워드 목록 내려받기

그중 20개 확인하기

stopwords를 필터링으로 제거해 의미 있는 단어만 추출

Stemming과 Lemmatization
문법적 또는 의미적으로 변화하는 단어의 원형을 찾는 것
Stemming: 원형 단어로 변환 시 일반적인 방법을 적용하거나 더 단순화된 방법을 적용해 원래 단어에서 일부 철자가 훼손된 어근 단어를 추출하는 경향이 있다
Lemmatization: 품사같은 문법적인 요소와 더 의미적인 부분을 감안해 정확한 철자로 된 어근 단어를 찾아준다
Porter, Lancaster, Snowball Stemmer같은 Stemmer 제공

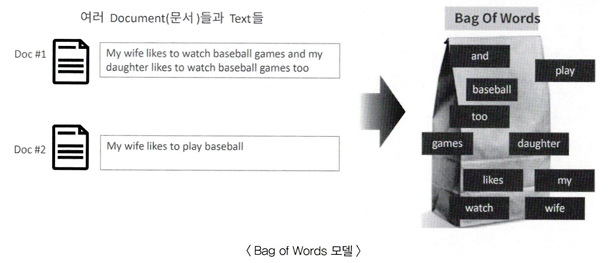
03. Bag of Words - BOW
BOW 모델은 문서가 가지는 모든 단어를 문맥이나 순서를 무시하고 이로갈적으로 단어에 대해 빈도 ㄱ밧을 부여해 피처 값을 추출하는 모델


단점
-문맥 의미 반영 부족
-희소 행렬 문제
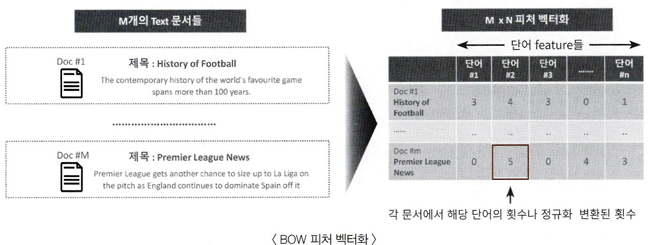
BOW 피처 벡터화
텍스트를 특정 의미를 가지는 숫자형 값인 벡터값으로 변환
모든 문서에서 모든 단어를 칼럼 형태로 나열하고 각 문서에서 해당 단어의 횟수나 정규화된 빈도를 값으로 부여하는 데이터 세트 모델로 변경하는 것
-카운트 기반의 벡터화 -> 문서에서 단어가 나타나는 횟수
-TF-IDF 기반의 벡터화 -> 텍스트 길고 문서 개수 많을 때 유용

사이킷런의 Count 및 TF-IDF 벡터화 구현: CountVectorizer, TildVectorizer
CountVectorizer 클래스: 카운트 기반의 벡터화를 구현한 클래스
fit()과 transform()을 통해 피처 벡터화된 객체를 반환한다

BOW 벡터화를 위한 희소 행렬
텍스트를 피처 단위로 벡터화해 변환하고 CSR 형태의 희소 행렬을 반환한다
희소 행렬 - COO 형식
0이 아닌 데이터만 별도의 데이터 배열에 저장하고 그 데이터가 가리키는 행과 열의 위치를 별도의 배열로 저장하는 방식
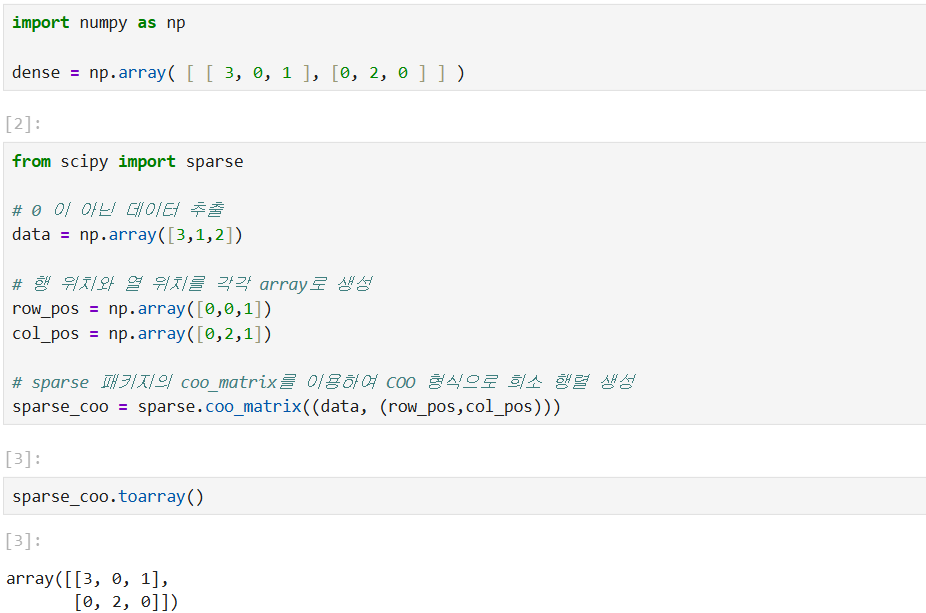
희소 행렬 -CSR 형식
COO 형식이 행과 열의 위치를 나타내기 위해서 반복적인 위치 데이터를 사용해야 하는 문제점을 해결한 방식




04. 텍스트 분류 실습 - 20 뉴스그룹 분류(509p)
텍스트 정규화
피처 벡터화 변환과 머신러닝 모델 학습/예측/평가
사이킷런 파이프라인 사용 및 GridSearchCV와의 결합
05. 감성 분석
감성 분석 소개
문서의 주관적인 감성/의견/감정/기분 등을 파악하기 위한 방법
문서 내 텍스트가 나타내는 여러 가지 주관적인 단어와 문맥을 기반으로 감성 수치를 계산하는 방법 이용
-지도학습
-비지도학습
지도학습 기반 감성 분석 실습 - IMDB 영화평(519p)
비지도학습 기반 감성 분석 소개
SentiWordNet을 이용한 감성 분석
VADER를 이용한 감성 분석
06. 토픽 모델링 - 20 뉴스그룹
문서 집합에 숨어 있는 주제를 찾아내는 것
자주 사용되는 기법: LSA, LDA
07. 문서 군집화 소개와 실습
문서 군집화 개념
비슷한 텍스트 구성의 문서를 군집화하는 것
Opinion Review 데이터셋을 이용한 문서 군집화 수행하기
군집별 핵십 단어 추출하기
clusters_centers_라는 속성
08. 문서 유사도
문서 유사도 측정 방법 - 코사인 유사도
두 벡터 사이의 사잇각 구해서 얼마나 유사한지 수치로 적용한 것
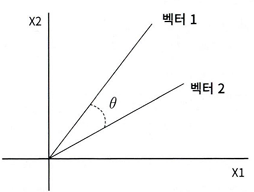
두 벡터 사잇각
import numpy as np
def cos_similarity(v1, v2):
dot_product = np.dot(v1, v2)
l2_norm = (np.sqrt(sum(np.square(v1))) * np.sqrt(sum(np.square(v2))))
similarity = dot_product / l2_norm
return similarity
문서 유사도 측정(554p)
09. 한글 텍스트 처리 - 네이버 영화 평점 감성 분석(558p)
한글 NLP 처리의 어려움
띄어쓰기와 다양한 조사 때문에 처리가 어렵다
KoNLPy 소개
파이썬의 대표적인 한글 형태소 패키지
데이터 로딩
10. 텍스트 분석 실습 - 캐글 Mercari Price Suggestion CHallenge(566p)
데이터 전처리
피처 인코딩과 피처 벡터화
릿지 회귀 모델 구축 및 평가
LightGBM 회귀 모델 구축과 앙상블을 이용한 최종 예측 평가
'AI' 카테고리의 다른 글
| [ML] 추천 시스템(Recommendations) (0) | 2026.03.03 |
|---|---|
| [ML] 군집화(Clustering) (0) | 2026.03.03 |
| [ML] 차원 축소(Dimension Reduction) (1) | 2026.03.02 |
| [ML] 회귀(Regression) (0) | 2026.03.02 |
| [ML] 분류(Classification) (0) | 2026.03.01 |

