
studio.heelab
[DL for CV] Image Classification with CNNs 본문
Lecture: https://www.youtube.com/watch?v=f3g1zGdxptI&list=PLoROMvodv4rOmsNzYBMe0gJY2XS8AQg16&index=5
1. DL Fundamentals Recap
mage Classification and Linear Classifiers: A method of defining input as a tensor and predicting class scores through a weight matrix $W$.
Loss Functions: Measures how well the model fits the data using functions such as Softmax or SVM.
Optimization: Utilizes algorithms like SGD or Adam to minimize loss. Notably, Adam's enduring impact was recognized with the 'Test of Time Award' at ICLR 2025.
Neural Networks and Backpropagation: To overcome the limitations of linear classifiers, non-linearity (ReLU) is added and layers are stacked. Backpropagation allows for the efficient calculation of gradients even within complex computational graphs.
2. Feature Representation vs. End-to-End Learning
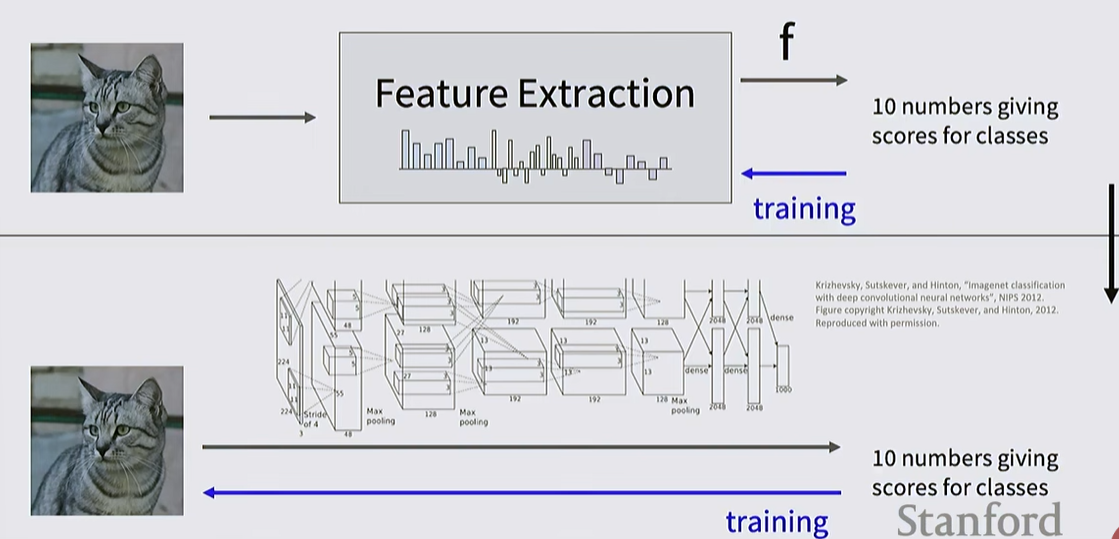
Traditional Approach (Feature Extraction): Features were extracted using human-engineered functions (e.g., Color Histograms, HOG) and then fed into a classifier.
Deep Learning Approach: The entire process, from raw pixels to final scores, is learned directly from data. This marks the victory of the paradigm that massive data and computation can outperform human intuition.
Image features

3. Core Concepts of Convolutional Neural Networks (CNN)
Limitations of FC Layers: Fully Connected layers flatten images into 1D vectors, which destroys the essential 2D spatial structure of the image.
Image features vs Convnet
Convolutional Neural Networks

Convolutional Layer:
- Performs template matching by sliding small Filters across the image while preserving its spatial structure.
- Each filter learns to recognize specific features like colors or edges; as layers get deeper, they recognize more complex structures such as eyes or wheels.
Convolution calculate Mechanism
Filter (Filter/Kernel): A filter smaller than the input image (e.g., 5 x 5) is used. This filter encompasses all input channels (Depth) and slides spatially across the input.
Template Matching: It calculates the Dot Product between the filter and a specific region of the image. This is a "template matching" process that measures how much of the pattern learned by the filter exists in that specific region of the image.

Activation Map: As a single filter slides across the entire image and collects the calculated scores, it forms a single 2D plane called an "Activation Map."

Using Multiple Filters: If multiple filters (e.g., 6 filters) are used, each one extracts different features. The resulting output becomes a 3D tensor with a number of channels equal to the number of filters used.


Key Hyperparameters:
- Filter Size (K): The width and height of the filter.
- Number of Filters (C_out): Determines the number of output channels.
- Padding (P): Adding zeros around the input to prevent the output size from shrinking.
- Stride (S): The interval at which the filter moves, used to downsample the data.
Filter Weights: Numerical values stored within the filter. They are initially set to random values and are subsequently learned from the data through backpropagation.
Bias: A single scalar value added to each filter.
Effective Receptive Field: As layers are stacked, the area of the original image that each activation node "sees" grows linearly or exponentially.
What Filters Learn (Visualization)
- Lower Layers: These layers learn simple templates that recognize edges, color contrasts, and blobs of specific colors.
- Higher Layers: As the network gets deeper, filters begin to recognize larger, more complex, and abstract structures such as eyes, wheels, or text fragments. All of these features are learned automatically from the data, rather than being manually engineered by humans.

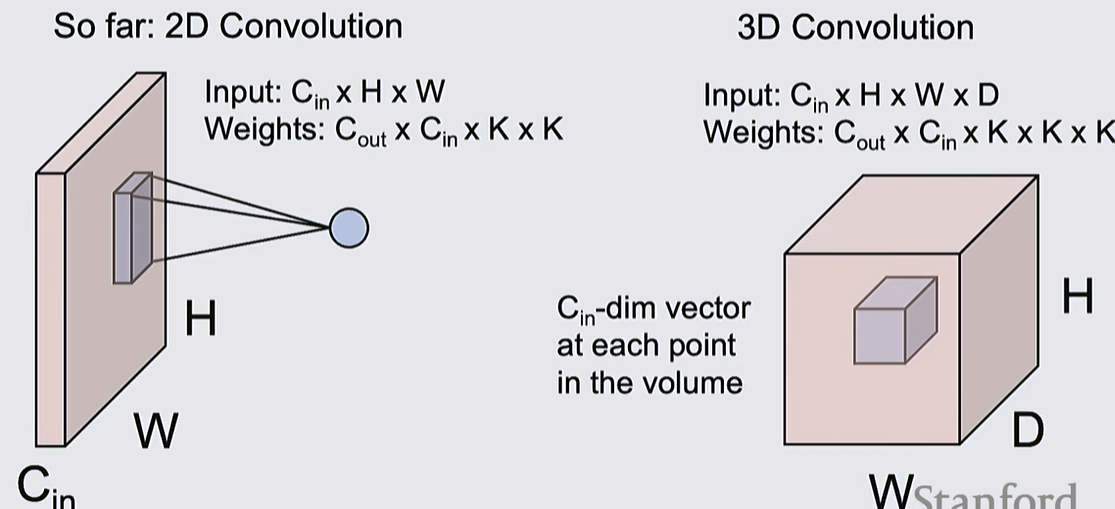
Other Types of Convolution
4. Pooling Layer

Role: Reduces spatial dimensions to decrease computational load and rapidly expand the receptive field. It is computationally much cheaper than convolution.
Max Pooling: A non-linear method that selects the maximum value within a set region; it is the most widely used pooling technique
Characteristics: Generally maintains the number of channels while reducing only height and width; padding is rarely used.
downsample

5. Characteristics and History of CNNs
Translation Equivariance: The property where translating an image and then convolving it yields the same result as convolving and then translating. This reflects the intuition that an object should be processed the same way regardless of its location in the image.
History: Started with LeNet in 1998 and experienced explosive growth following AlexNet in 2012.
Current Status: Since 2020, Transformers have begun to supplement or replace CNNs in image processing, but CNNs still provide vital intuition and practicality
'MMAILab' 카테고리의 다른 글
| [DL for CV] Training CNNs and CNN Architectures (0) | 2026.03.05 |
|---|---|
| [DL for CV] Neural Networks & Backpropagation (0) | 2026.03.04 |
| [DL for CV] Regularization & Optimization (0) | 2026.03.04 |
| [DL for CV] Image Classification with Linear Classifiers (0) | 2026.03.04 |
| [DL for CV] Introduction (1) | 2026.03.04 |



