
studio.heelab
[DL for CV] Training CNNs and CNN Architectures 본문
Lecture: https://www.youtube.com/watch?v=aVJy4O5TOk8&list=PLoROMvodv4rOmsNzYBMe0gJY2XS8AQg16&index=6
1. Building Blocks of CNNs
Components of CNNs

Convolutional Layers: Filters (kernels) slide across the image, producing an activation map through dot products. The output depth must match the number of filters used, and the filter depth of the next layer must equal the preceding output's depth.
Pooling Layers: These summarize information by reducing the spatial (width and height) dimensions of the image. Max pooling (selecting the maximum value) and Average pooling (calculating the average) are commonly used.
Fully Connected (FC) Layers: A structure where matrix multiplication is followed by an activation function, primarily used at the end of the model for classification.
Normalization Layers: These normalize input data by calculating the mean and standard deviation, followed by scaling and shifting with learnable parameters.
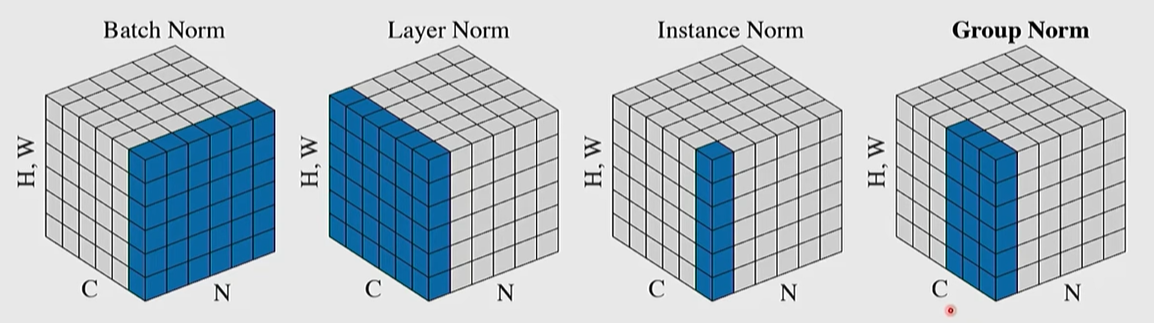
Layer Norm: Calculates statistics across all channels and spatial dimensions for each sample; widely used in Transformer models.
Batch Norm: Calculates statistics for each channel across the mini-batch.
Dropout: A regularization technique that randomly sets some activation values to zero during training to prevent the model from over-relying on specific features. During testing, all activations are used, but they are scaled by the dropout probability (p) to maintain the same magnitude as during training.


2. Activation Functions
Purpose: To introduce nonlinearity into the model.
Sigmoid: Used in the past, but now rarely used because gradients vanish (vanishing gradient problem) when input values are very large or small.
ReLU: Extremely popular because the gradient remains 1 for positive values, leading to fast training and low computational cost. However, it has the drawback of gradients becoming zero in the negative region.

GELU and SiLU (Swish): These address ReLU's weaknesses by having smooth curves near zero and maintaining subtle gradients in the negative region. GELU is currently the standard activation function for Transformer models.

3. Major CNN Architectures
VGG Net
Employs a method of stacking multiple small $3\times3$ filters. Stacking three $3\times3$ filters provides the same receptive field as one $7\times7$ filter but is more efficient, using fewer parameters and providing more non-linearities.

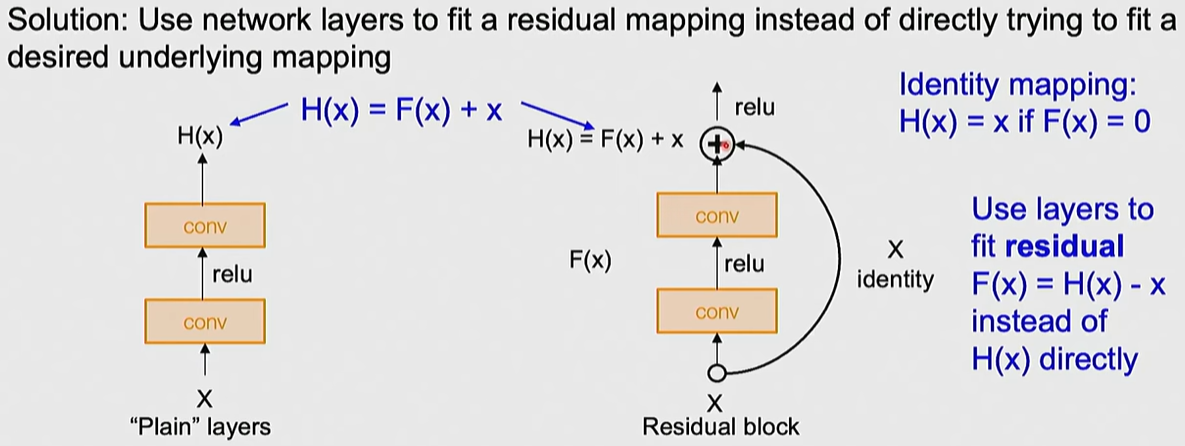
ResNet (Residual Networks)
- Motivation: Developed to solve optimization issues where training and test errors increased as networks grew deeper (not an overfitting problem).
- Core Principle: Introduces Residual Connections that add the input $x$ to the output, learning F(x) + x. This allows the model to learn identity mapping more easily, enabling the training of networks with over 100 layers.
- Structural Features: Periodically doubles the number of filters and downsamples spatial dimensions.
4. Weight Initialization
If weights are too small, activations converge to zero; if too large, values explode.
- Kaiming (He) Initialization: The standard method for modern CNNs using ReLU, which keeps the variance of activations constant using the formula
5 Training CNNs
Data Preprocessing and Augmentation:
- Preprocessing: Normalizing each channel by subtracting the mean and dividing by the standard deviation.
- Data Augmentation: Increases data volume and improves generalization by applying horizontal flips, random resized crops, and color jitter during training.

Transfer Learning: Utilizing models pre-trained on large datasets like ImageNet when data is scarce.
- Methods: Either freezing existing weights and training only the final classification layer (Feature Extraction) or retraining the entire model with a low learning rate (Fine-tuning).

Hyperparameter Selection and Debugging:
- Debugging Strategy: First, check if the model can overfit a tiny amount of data (e.g., 1 sample) to a loss of zero to find code bugs.
- Search Method: Random search is recommended over grid search for efficiently finding crucial hyperparameters like learning rate.
- Monitoring: Determine overfitting by tracking loss and accuracy curves for both training and validation data.

'MMAILab' 카테고리의 다른 글
| [DL for CV] Image Classification with CNNs (0) | 2026.03.05 |
|---|---|
| [DL for CV] Neural Networks & Backpropagation (0) | 2026.03.04 |
| [DL for CV] Regularization & Optimization (0) | 2026.03.04 |
| [DL for CV] Image Classification with Linear Classifiers (0) | 2026.03.04 |
| [DL for CV] Introduction (1) | 2026.03.04 |



